











Please enter the answer below before you can view the full text.
8+1=
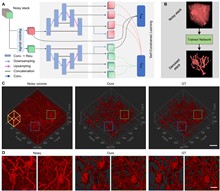
Volumetric imaging is increasingly in demand for its precision in statistically visualizing and analyzing the intricacies of biological phenomena. To visualize the intricate details of these minute structures and facilitate the analysis in biomedical research, high-signal-to-noise ratio (SNR) images are indispensable. However, the inevitable noise presents a significant barrier to imaging qualities. Here, we propose SelfMirror, a self-supervised deep-learning denoising method for volumetric image reconstruction. SelfMirror is developed based on the insight that the variation of biological structure is continuous and smooth; when the sampling interval in volumetric imaging is sufficiently small, the similarity of neighboring slices in terms of the spatial structure becomes apparent. Such similarity can be used to train our proposed network to revive the signals and suppress the noise accurately. The denoising performance of SelfMirror exhibits remarkable robustness and fidelity even in extremely low-SNR conditions. We demonstrate the broad applicability of SelfMirror on multiple imaging modalities, including two-photon microscopy, confocal microscopy, expansion microscopy, computed tomography, and 3D electron microscopy. This versatility extends from single neuron cells to tissues and organs, highlighting SelfMirror’s potential for integration into diverse imaging and analysis pipelines.
Fringe projection profilometry (FPP) is a method that determines height by analyzing distortional fringes, which is widely used in high-accuracy 3D imaging. Now, one major reason limiting imaging speed in FPP is the projection device; the capture speed of high-speed cameras far exceeds the projection frequency. Among various devices, an LED array can exceed the speed of a high-speed camera. However, non-sinusoidal fringe patterns in the LED array systems can arise from several factors that will reduce the accuracy, such as the spacing between adjacent LEDs, the inconsistency in brightness across different LEDs, and the residual high-order harmonics in binary defocusing projection. It is challenging to resolve by other methods. In this paper, we propose a method that creates a look-up table using system calibration data of phase-height models. Then we utilize the look-up table to compensate for the phase error during the reconstructing process. The foundation of the proposed method relies on the time-invariance of systematic error; any factor that impacts the sinusoidal characteristic would present as an anomaly in the unwrapped phase. Experiments have demonstrated that the root mean square errors (RMSEs) of the results yielded by the proposed method were reduced by over 90% compared to those yielded by the traditional method, reaching 20 μm accuracy. This paper offers an alternative approach for high-speed and high-accuracy 3D imaging with an LED array and presents a workable solution for addressing complex errors from non-sinusoidal fringes.
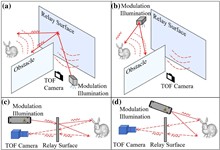
The technique of imaging or tracking objects outside the field of view (FOV) through a reflective relay surface, usually called non-line-of-sight (NLOS) imaging, has been a popular research topic in recent years. Although NLOS imaging can be achieved through methods such as detector design, optical path inverse operation algorithm design, or deep learning, challenges such as high costs, complex algorithms, and poor results remain. This study introduces a simple algorithm-based rapid depth imaging device, namely, the continuous-wave time-of-flight range imaging camera (CW-TOF camera), to address the decoupled imaging challenge of differential scattering characteristics in an object-relay surface by quantifying the differential scattering signatures through statistical analysis of light propagation paths. A scalable scattering mapping (SSM) theory has been proposed to explain the degradation process of clear images. High-quality NLOS object 3D imaging has been achieved through a data-driven approach. To verify the effectiveness of the proposed algorithm, experiments were conducted using an optical platform and real-world scenarios. The objects on the optical platform include plaster sculptures and plastic letters, while relay surfaces consist of polypropylene (PP) plastic boards, acrylic boards, and standard Lambertian diffusers. In real-world scenarios, the object is clothing, with relay surfaces including painted doors and white plaster walls. Imaging data were collected for different combinations of objects and relay surfaces for training and testing, totaling 210,000 depth images. The reconstruction of NLOS images in the laboratory and real-world is excellent according to subjective evaluation; thus, our approach can realize NLOS imaging in harsh natural scenes and advances the practical application of NLOS imaging.
Recently, infrared polarization imaging technology has become a research hotspot due to its ability to better resolve the physicochemical properties of objects and significantly enhance the target characteristics. However, the traditional infrared polarization imaging is limited to similar imaging mechanism restrictions, and it is difficult to acquire the polarization information of a wide-area posture in real time. Therefore, we report a combination of hardware and software for super-wide-field-of-view long-wave infrared gaze polarization imaging technology. Utilizing the non-similar imaging theory and adopting the inter-lens coupling holographic line-grid infrared polarization device scheme, we designed the infrared gazing polarized lens with a field-of-view of over 160°. Based on the fusion of infrared intensity images and infrared polarization images, a multi-strategy detail feature extraction and fusion network is constructed. Super-wide-field-of-view (150°×120°), large face array (1040×830), detail-rich infrared fusion images are acquired during the test. We have accomplished the tasks of vehicle target detection and infrared camouflage target recognition efficiently using the fusion images, and verified the superiority of recognizing far-field targets. Our implementation should enable and empower applications in machine vision, intelligent driving, and target detection under complex environments.
Deep learning has rapidly advanced amidst the proliferation of large models, leading to challenges in computational resources and power consumption. Optical neural networks (ONNs) offer a solution by shifting computation to optics, thereby leveraging the benefits of low power consumption, low latency, and high parallelism. The current training paradigm for ONNs primarily relies on backpropagation (BP). However, the reliance is incompatible with potential unknown processes within the system, which necessitates detailed knowledge and precise mathematical modeling of the optical process. In this paper, we present a pre-sensor multilayer ONN with nonlinear activation, utilizing a forward-forward algorithm to directly train both optical and digital parameters, which replaces the traditional backward pass with an additional forward pass. Our proposed nonlinear optical system demonstrates significant improvements in image classification accuracy, achieving a maximum enhancement of 9.0%. It also validates the efficacy of training parameters in the presence of unknown nonlinear components in the optical system. The proposed training method addresses the limitations of BP, paving the way for applications with a broader range of physical transformations in ONNs.
Large-volume photoacoustic microscopy (PAM) or rapid PAM has attracted increasing attention in biomedical applications due to its ability to provide detailed structural and functional information on tumor pathophysiology and the neuroimmune microenvironment. Non-diffracting beams, such as Airy beams, offer extended depth-of-field (DoF), while sparse image reconstruction using deep learning enables image recovery for rapid imaging. However, Airy beams often introduce side-lobe artifacts, and achieving both extended DoF and rapid imaging remains a challenge, hindering PAM’s adoption as a routine large-volume and repeatable monitoring tool. To address these challenges, we developed multitask learning-powered large-volume, rapid photoacoustic microscopy with Airy beams (ML-LR-PAM). This approach integrates advanced software and hardware solutions designed to mitigate side-lobe artifacts and achieve super-resolution reconstruction. Unlike previous methods that neglect the simultaneous optimization of these aspects, our approach bridges this gap by employing scaled dot-product attention mechanism (SDAM) Wasserstein-based CycleGAN (SW-CycleGAN) for artifact reduction and high-resolution, large-volume imaging. We anticipate that ML-LR-PAM, through this integration, will become a standard tool in both biomedical research and clinical practice.
Polarimetric dehazing is an effective way to enhance the quality of images captured in foggy weather. However, images of essential polarization parameters are vulnerable to noise, and the brightness of dehazed images is usually unstable due to different environmental illuminations. These two weaknesses reveal that current polarimetric dehazing algorithms are not robust enough to deal with different scenarios. This paper proposes a novel, to our knowledge, and robust polarimetric dehazing algorithm to enhance the quality of hazy images, where a low-rank approximation method is used to obtain low-noise polarization parameter images. Besides, in order to improve the brightness stability of the dehazed image and thus keep the image have more details within the standard dynamic range, this study proposes a multiple virtual-exposure fusion (MVEF) scheme to process the dehazed image (usually having a high dynamic range) obtained through polarimetric dehazing. Comparative experiments show that the proposed dehazing algorithm is robust and effective, which can significantly improve overall quality of hazy images captured under different environments.
The COVID-19 pandemic continues to significantly impact people’s lives worldwide, emphasizing the critical need for effective detection methods. Many existing deep learning-based approaches for COVID-19 detection offer high accuracy but demand substantial computing resources, time, and energy. In this study, we introduce an optical diffractive neural network (ODNN-COVID), which is characterized by low power consumption, efficient parallelization, and fast computing speed for COVID-19 detection. In addition, we explore how the physical parameters of ODNN-COVID affect its diagnostic performance. We identify the F number as a key parameter for evaluating the overall detection capabilities. Through an assessment of the connectivity of the diffractive network, we established an optimized range of F number, offering guidance for constructing optical diffractive neural networks. In the numerical simulations, a three-layer system achieves an impressive overall accuracy of 92.64% and 88.89% in binary- and three-classification diagnostic tasks. For a single-layer system, the simulation accuracy of 84.17% and the experimental accuracy of 80.83% can be obtained with the same configuration for the binary-classification task, and the simulation accuracy is 80.19% and the experimental accuracy is 74.44% for the three-classification task. Both simulations and experiments validate that the proposed optical diffractive neural network serves as a passive optical processor for effective COVID-19 diagnosis, featuring low power consumption, high parallelization, and fast computing capabilities. Furthermore, ODNN-COVID exhibits versatility, making it adaptable to various image analysis and object classification tasks related to medical fields owing to its general architecture.
In order to harness diffractive neural networks (DNNs) for tasks that better align with real-world computer vision requirements, the incorporation of gray scale is essential. Currently, DNNs are not powerful enough to accomplish gray-scale image processing tasks due to limitations in their expressive power. In our work, we elucidate the relationship between the improvement in the expressive power of DNNs and the increase in the number of phase modulation layers, as well as the optimization of the Fresnel number, which can describe the diffraction process. To demonstrate this point, we numerically trained a double-layer DNN, addressing the prerequisites for intensity-based gray-scale image processing. Furthermore, we experimentally constructed this double-layer DNN based on digital micromirror devices and spatial light modulators, achieving eight-level intensity-based gray-scale image classification for the MNIST and Fashion-MNIST data sets. This optical system achieved the maximum accuracies of 95.10% and 80.61%, respectively.
Accurately measuring the complex transmission matrix (CTM) of the scattering medium (SM) holds critical significance for applications in anti-scattering optical imaging, phototherapy, and optical neural networks. Non-interferometric approaches, utilizing phase retrieval algorithms, can robustly extract the CTM from the speckle patterns formed by multiple probing fields traversing the SM. However, in cases where an amplitude-type spatial light modulator is employed for probing field modulation, the absence of phase control frequently results in the convergence towards a local optimum, undermining the measurement accuracy. Here, we propose a high-accuracy CTM retrieval (CTMR) approach based on regional phase differentiation (RPD). It incorporates a sequence of additional phase masks into the probing fields, imposing a priori constraints on the phase retrieval algorithms. By distinguishing the variance of speckle patterns produced by different phase masks, the RPD-CTMR can effectively direct the algorithm towards a solution that closely approximates the CTM of the SM. We built a prototype of a digital micromirror device modulated RPD-CTMR. By accurately measuring the CTM of diffusers, we achieved an enhancement in the peak-to-background ratio of anti-scattering focusing by a factor of 3.6, alongside a reduction in the bit error rate of anti-scattering image transmission by a factor of 24. Our proposed approach aims to facilitate precise modulation of scattered optical fields, thereby fostering advancements in diverse fields including high-resolution microscopy, biomedical optical imaging, and optical communications.
The optical microscopy image plays an important role in scientific research through the direct visualization of the nanoworld, where the imaging mechanism is described as the convolution of the point spread function (PSF) and emitters. Based on a priori knowledge of the PSF or equivalent PSF, it is possible to achieve more precise exploration of the nanoworld. However, it is an outstanding challenge to directly extract the PSF from microscopy images. Here, with the help of self-supervised learning, we propose a physics-informed masked autoencoder (PiMAE) that enables a learnable estimation of the PSF and emitters directly from the raw microscopy images. We demonstrate our method in synthetic data and real-world experiments with significant accuracy and noise robustness. PiMAE outperforms DeepSTORM and the Richardson–Lucy algorithm in synthetic data tasks with an average improvement of 19.6% and 50.7% (35 tasks), respectively, as measured by the normalized root mean square error (NRMSE) metric. This is achieved without prior knowledge of the PSF, in contrast to the supervised approach used by DeepSTORM and the known PSF assumption in the Richardson–Lucy algorithm. Our method, PiMAE, provides a feasible scheme for achieving the hidden imaging mechanism in optical microscopy and has the potential to learn hidden mechanisms in many more systems.
Imaging through non-static and optically thick scattering media such as dense fog, heavy smoke, and turbid water is crucial in various applications. However, most existing methods rely on either active and coherent light illumination, or image priors, preventing their application in situations where only passive illumination is possible. In this study we present a universal passive method for imaging through dense scattering media that does not depend on any prior information. Combining the selection of small-angle components out of the incoming information-carrying scattering light and image enhancement algorithm that incorporates time-domain minimum filtering and denoising, we show that the proposed method can dramatically improve the signal-to-interference ratio and contrast of the raw camera image in outfield experiments.
Information retrieval from visually random optical speckle patterns is desired in many scenarios yet considered challenging. It requires accurate understanding or mapping of the multiple scattering process, or reliable capability to reverse or compensate for the scattering-induced phase distortions. In whatever situation, effective resolving and digitization of speckle patterns are necessary. Nevertheless, on some occasions, to increase the acquisition speed and/or signal-to-noise ratio (SNR), speckles captured by cameras are inevitably sampled in the sub-Nyquist domain via pixel binning (one camera pixel contains multiple speckle grains) due to finite size or limited bandwidth of photosensors. Such a down-sampling process is irreversible; it undermines the fine structures of speckle grains and hence the encoded information, preventing successful information extraction. To retrace the lost information, super-resolution interpolation for such sub-Nyquist sampled speckles is needed. In this work, a deep neural network, namely SpkSRNet, is proposed to effectively up sample speckles that are sampled below 1/10 of the Nyquist criterion to well-resolved ones that not only resemble the comprehensive morphology of original speckles (decompose multiple speckle grains from one camera pixel) but also recover the lost complex information (human face in this study) with high fidelity under normal- and low-light conditions, which is impossible with classic interpolation methods. These successful speckle super-resolution interpolation demonstrations are essentially enabled by the strong implicit correlation among speckle grains, which is non-quantifiable but could be discovered by the well-trained network. With further engineering, the proposed learning platform may benefit many scenarios that are physically inaccessible, enabling fast acquisition of speckles with sufficient SNR and opening up new avenues for seeing big and seeing clearly simultaneously in complex scenarios.
Coded exposure photography is a promising computational imaging technique capable of addressing motion blur much better than using a conventional camera, via tailoring invertible blur kernels. However, existing methods suffer from restrictive assumptions, complicated preprocessing, and inferior performance. To address these issues, we proposed an end-to-end framework to handle general motion blurs with a unified deep neural network, and optimize the shutter’s encoding pattern together with the deblurring processing to achieve high-quality sharp images. The framework incorporates a learnable flutter shutter sequence to capture coded exposure snapshots and a learning-based deblurring network to restore the sharp images from the blurry inputs. By co-optimizing the encoding and the deblurring modules jointly, our approach avoids exhaustively searching for encoding sequences and achieves an optimal overall deblurring performance. Compared with existing coded exposure based motion deblurring methods, the proposed framework eliminates tedious preprocessing steps such as foreground segmentation and blur kernel estimation, and extends coded exposure deblurring to more general blind and nonuniform cases. Both simulation and real-data experiments demonstrate the superior performance and flexibility of the proposed method.
Spectral compressive imaging (SCI) is able to encode a high-dimensional hyperspectral image into a two-dimensional snapshot measurement, and then use algorithms to reconstruct the spatio-spectral data-cube. At present, the main bottleneck of SCI is the reconstruction algorithm, and state-of-the-art (SOTA) reconstruction methods generally face problems of long reconstruction times and/or poor detail recovery. In this paper, we propose a hybrid network module, namely, a convolution and contextual Transformer (CCoT) block, that can simultaneously acquire the inductive bias ability of convolution and the powerful modeling ability of Transformer, which is conducive to improving the quality of reconstruction to restore fine details. We integrate the proposed CCoT block into a physics-driven deep unfolding framework based on the generalized alternating projection (GAP) algorithm, and further propose the GAP-CCoT network. Finally, we apply the GAP-CCoT algorithm to SCI reconstruction. Through experiments on a large amount of synthetic data and real data, our proposed model achieves higher reconstruction quality (>2 dB in peak signal-to-noise ratio on simulated benchmark datasets) and a shorter running time than existing SOTA algorithms by a large margin. The code and models are publicly available at https://github.com/ucaswangls/GAP-CCoT.
Conventional phase retrieval algorithms for coherent diffractive imaging (CDI) require many iterations to deliver reasonable results, even using a known mask as a strong constraint in the imaging setup, an approach known as masked CDI. This paper proposes a fast and robust phase retrieval method for masked CDI based on the alternating direction method of multipliers (ADMM). We propose a plug-and-play ADMM to incorporate the prior knowledge of the mask, but note that commonly used denoisers are not suitable as regularizers for complex-valued latent images directly. Therefore, we develop a regularizer based on the structure tensor and Harris corner detector. Compared with conventional phase retrieval methods, our technique can achieve comparable reconstruction results with less time for the masked CDI. Moreover, validation experiments on real in situ CDI data for both intensity and phase objects show that our approach is more than 100 times faster than the baseline method to reconstruct one complex-valued image, making it possible to be used in challenging situations, such as imaging dynamic objects. Furthermore, phase retrieval results for single diffraction patterns show the robustness of the proposed ADMM.
Since Hanbury Brown and Twiss revealed the photon bunching effect of a thermal light source in 1956, almost all studies in correlation optics have been based on light’s intensity fluctuation, regardless of fact that the polarization fluctuation is a basic attribute of natural light. In this work, we uncover the veil of the polarization fluctuation and corresponding photon correlations by proposing a new light source model, termed pseudo-natural light, embodying both intensity and polarization fluctuations. Unexpectedly, the strong antibunching and superbunching effects can be simultaneously realized in such a new source, whose second-order correlation coefficient g(2) can be continuously modulated across 1. For the symmetric Bernoulli distribution of the polarization fluctuation, particularly, g(2) can be in principle from 0 to unlimitedly large. In pseudo-natural light, while the bunching effects of both intensity and polarization fluctuations enhance the bunching to superbunching photon correlation, the antibunching correlation of the polarization fluctuation can also be extracted through the procedure of division operation in the experiment. The antibunching effect and the combination with the bunching one will arouse new applications in quantum imaging. As heuristic examples, we carry out high-quality positive or negative ghost imaging, and devise high-efficiency polarization-sensitive and edge-enhanced imaging. This work, therefore, sheds light on the development of multiple and broad correlation functions for natural light.
Scattering-induced glares hinder the detection of weak objects in various scenarios. Recent advances in wavefront shaping show one can not only enhance intensities through constructive interference but also suppress glares within a targeted region via destructive interference. However, due to the lack of a physical model and mathematical guidance, existing approaches have generally adopted a feedback-based scheme, which requires time-consuming hardware iteration. Moreover, glare suppression with up to tens of speckles was demonstrated by controlling thousands of independent elements. Here, we reported the development of a method named two-stage matrix-assisted glare suppression (TAGS), which is capable of suppressing glares at a large scale without triggering time-consuming hardware iteration. By using the TAGS, we experimentally darkened an area containing 100 speckles by controlling only 100 independent elements, achieving an average intensity of only 0.11 of the original value. It is also noticeable that the TAGS is computationally efficient, which only takes 0.35 s to retrieve the matrix and 0.11 s to synthesize the wavefront. With the same number of independent controls, further demonstrations on suppressing larger scales up to 256 speckles were also reported. We envision that the superior performance of the TAGS at a large scale can be beneficial to a variety of demanding imaging tasks under a scattering environment.
To achieve better performance of a diffractive deep neural network, increasing its spatial complexity (neurons and layers) is commonly used. Subject to physical laws of optical diffraction, a deeper diffractive neural network (DNN) would be more difficult to implement, and the development of DNN is limited. In this work, we found controlling the Fresnel number can increase DNN’s capability of expression and its spatial complexity is even less. DNN with only one phase modulation layer was proposed and experimentally realized at 515 nm. With the optimal Fresnel number, the single-layer DNN reached a maximum accuracy of 97.08% in the handwritten digits recognition task.
Lensless scattering imaging is a prospective approach to microscopy in which a high-resolution image of an object is reconstructed from one or more measured speckle patterns, thus providing a solution in situations where the use of imaging optics is not possible. However, current lensless scattering imaging methods are typically limited by the need for a light source with a narrowband spectrum. Here, we propose two general approaches that enable single-shot lensless scattering imaging under broadband illumination in both noninvasive [without point spread function (PSF) calibration] and invasive (with PSF calibration) modes. The first noninvasive approach is based on a numerical refinement of the broadband pattern in the cepstrum incorporated with a modified phase retrieval strategy. The latter invasive approach is correlation inspired and generalized within a computational optimization framework. Both approaches are experimentally verified using visible radiation with a full-width-at-half-maximum bandwidth as wide as 280 nm (Δλ/λ=44.8%) and a speckle contrast ratio as low as 0.0823. Because of its generality and ease of implementation, we expect this method to find widespread applications in ultrafast science, passive sensing, and biomedical applications.
Full-color imaging is of critical importance in digital pathology for analyzing labeled tissue sections. In our previous cover story [Sci. China: Phys., Mech. Astron.64, 114211 (2021)SCPMCL1674-734810.1007/s11433-021-1730-x], a color transfer approach was implemented on Fourier ptychographic microscopy (FPM) for achieving high-throughput full-color whole slide imaging without mechanical scanning. The approach was able to reduce both acquisition and reconstruction time of FPM by three-fold with negligible trade-off on color accuracy. However, the method cannot properly stain samples with two or more dyes due to the lack of spatial constraints in the color transfer process. It also requires a high computation cost in histogram matching of individual patches. Here we report a modified full-color imaging algorithm for FPM, termed color-transfer filtering FPM (CFFPM). In CFFPM, we replace the original histogram matching process with a combination of block processing and trilateral spatial filtering. The former step reduces the search of the solution space for colorization, and the latter introduces spatial constraints that match the low-resolution measurement. We further adopt an iterative process to refine the results. We show that this method can perform accurate and fast color transfer for various specimens, including those with multiple stains. The statistical results of 26 samples show that the average root mean square error is only 1.26% higher than that of the red-green-blue sequential acquisition method. For some cases, CFFPM outperforms the sequential method because of the coherent artifacts introduced by dust particles. The reported CFFPM strategy provides a turnkey solution for digital pathology via computational optical imaging.
The estimation of the transmission matrix of a disordered medium is a challenging problem in disordered photonics. Usually, its reconstruction relies on a complex inversion that aims at connecting a fully controlled input to the deterministic interference of the light field scrambled by the device. At the moment, iterative phase retrieval protocols provide the fastest reconstructing frameworks, converging in a few tens of iterations. Exploiting the knowledge of speckle correlations, we construct a new phase retrieval algorithm that reduces the computational cost to a single iteration. Besides being faster, our method is practical because it accepts fewer measurements than state-of-the-art protocols. Thanks to reducing computation time by one order of magnitude, our result can be a step forward toward real-time optical imaging that exploits disordered devices.
Phase retrieval from fringe images is essential to many optical metrology applications. In the field of fringe projection profilometry, the phase is often obtained with systematic errors if the fringe pattern is not a perfect sinusoid. Several factors can account for non-sinusoidal fringe patterns, such as the non-linear input–output response (e.g., the gamma effect) of digital projectors, the residual harmonics in binary defocusing projection, and the image saturation due to intense reflection. Traditionally, these problems are handled separately with different well-designed methods, which can be seen as “one-to-one” strategies. Inspired by recent successful artificial intelligence-based optical imaging applications, we propose a “one-to-many” deep learning technique that can analyze non-sinusoidal fringe images resulting from different non-sinusoidal factors and even the coupling of these factors. We show for the first time, to the best of our knowledge, a trained deep neural network can effectively suppress the phase errors due to various kinds of non-sinusoidal patterns. Our work paves the way to robust and powerful learning-based fringe analysis approaches.
Ghost imaging (GI) can nonlocally image objects by exploiting the fluctuation characteristics of light fields, where the spatial resolution is determined by the normalized second-order correlation function g(2). However, the spatial shift-invariant property of g(2) is distorted when the number of samples is limited, which hinders the deconvolution methods from improving the spatial resolution of GI. In this paper, based on prior imaging systems, we propose a preconditioned deconvolution method to improve the imaging resolution of GI by refining the mutual coherence of a sampling matrix in GI. Our theoretical analysis shows that the preconditioned deconvolution method actually extends the deconvolution technique to GI and regresses into the classical deconvolution technique for the conventional imaging system. The imaging resolution of GI after preconditioning is restricted to the detection noise. Both simulation and experimental results show that the spatial resolution of the reconstructed image is obviously enhanced by using the preconditioned deconvolution method. In the experiment, 1.4-fold resolution enhancement over Rayleigh criterion is achieved via the preconditioned deconvolution. Our results extend the deconvolution technique that is only applicable to spatial shift-invariant imaging systems to all linear imaging systems, and will promote their applications in biological imaging and remote sensing for high-resolution imaging demands.
Due to its ability of optical sectioning and low phototoxicity, z-stacking light-sheet microscopy has been the tool of choice for in vivo imaging of the zebrafish brain. To image the zebrafish brain with a large field of view, the thickness of the Gaussian beam inevitably becomes several times greater than the system depth of field (DOF), where the fluorescence distributions outside the DOF will also be collected, blurring the image. In this paper, we propose a 3D deblurring method, aiming to redistribute the measured intensity of each pixel in a light-sheet image to in situ voxels by 3D deconvolution. By introducing a Hessian regularization term to maintain the continuity of the neuron distribution and using a modified stripe-removal algorithm, the reconstructed z-stack images exhibit high contrast and a high signal-to-noise ratio. These performance characteristics can facilitate subsequent processing, such as 3D neuron registration, segmentation, and recognition.
Edge enhancement is a fundamental and important topic in imaging and image processing, as perception of edge is one of the keys to identify and comprehend the contents of an image. Edge enhancement can be performed in many ways, through hardware or computation. Existing methods, however, have been limited in free space or clear media for optical applications; in scattering media such as biological tissue, light is multiple scattered, and information is scrambled to a form of seemingly random speckles. Although desired, it is challenging to accomplish edge enhancement in the presence of multiple scattering. In this work, we introduce an implementation of optical wavefront shaping to achieve efficient edge enhancement through scattering media by a two-step operation. The first step is to acquire a hologram after the scattering medium, where information of the edge region is accurately encoded, while that of the nonedge region is intentionally encoded with inadequate accuracy. The second step is to decode the edge information by time-reversing the scattered light. The capability is demonstrated experimentally, and, further, the performance, as measured by the edge enhancement index (EI) and enhancement-to-noise ratio (ENR), can be controlled easily through tuning the beam ratio. EI and ENR can be reinforced by ~8.5 and ~263 folds, respectively. To the best of our knowledge, this is the first demonstration that edge information of a spatial pattern can be extracted through strong turbidity, which can potentially enrich the comprehension of actual images obtained from a complex environment.
Prior-free imaging beyond the memory effect (ME) is critical to seeing through the scattering media. However, methods proposed to exceed the ME range have suffered from the availability of prior information of imaging targets. Here, we propose a blind target position detection for large field-of-view scattering imaging. Only exploiting two captured multi-target near-field speckles at different imaging distances, the unknown number and locations of the isolated imaging targets are blindly reconstructed via the proposed scaling-vector-based detection. Autocorrelations can be calculated for the speckle regions centered by the derived positions via low-cross-talk region allocation strategy. Working with the modified phase retrieval algorithm, the complete scene of the multiple targets exceeding the ME range can be reconstructed without any prior information. The effectiveness of the proposed algorithm is verified by testing on a real scattering imaging system.
High-speed ophthalmic optical coherence tomography (OCT) systems are of interest because they allow rapid, motion-free, and wide-field retinal imaging. Space-division multiplexing optical coherence tomography (SDM-OCT) is a high-speed imaging technology that takes advantage of the long coherence length of microelectromechanical vertical cavity surface emitting laser sources to multiplex multiple images along a single imaging depth. We demonstrate wide-field retinal OCT imaging, acquired at an effective A-scan rate of 800,000 A-scans/s with volumetric images covering up to 12.5 mm×7.4 mm on the retina and captured in less than 1 s. A clinical feasibility study was conducted to compare the ophthalmic SDM-OCT with commercial OCT systems, illustrating the high-speed capability of SDM-OCT in a clinical setting.
Phase imaging always deals with the problem of phase invisibility when capturing objects with existing light sensors. However, there is a demand for multiplane full intensity measurements and iterative propagation process or reliance on reference in most conventional approaches. In this paper, we present an end-to-end compressible phase imaging method based on deep neural networks, which can implement phase estimation using only binary measurements. A thin diffuser as a preprocessor is placed in front of the image sensor to implicitly encode the incoming wavefront information into the distortion and local variation of the generated speckles. Through the trained network, the phase profile of the object can be extracted from the discrete grains distributed in the low-bit-depth pattern. Our experiments demonstrate the faithful reconstruction with reasonable quality utilizing a single binary pattern and verify the high redundancy of the information in the intensity measurement for phase recovery. In addition to the advantages of efficiency and simplicity compared to now available imaging methods, our model provides significant compressibility for imaging data and can therefore facilitate the low-cost detection and efficient data transmission.
The scattering medium is usually thought to have a negative effect on the imaging process. In this paper, it is shown that the imaging quality of reflective ghost imaging (GI) in the scattering medium can be improved effectively when the binary method is used. By the experimental and the numerical results, it is proved that the existence of the scattering medium is just the cause of this phenomenon, i.e., the scattering medium has a positive effect on the imaging quality of reflective GI. During this process, the effect from the scattering medium behaves as the random noise which makes the imaging quality of binary ghost imaging have an obvious improvement.